大語言模型(LLM)已經在多個領域展示出了卓越的性能和巨大的潛力,然而,要想真正發揮出這些模型的強大能力,需要強大的算力基礎設施,而芯片是關鍵。
千呼萬喚始出來,第五代英特爾?? 至強?? 可擴展處理器,它來了!
若是用一句話來概括它的特點,那就是——AI味道越發得濃厚。
以訓練、推理大模型為例:
● 與第四代相比,訓練性能提升多達29%,推理性能提升高達42%;
● 與第三代相比,AI訓練和推理性能提升高達14倍。

什么概念?
現在若是將不超過200億參數的模型“投喂”給第五代至強?? 可擴展處理器,那么時延將低到不超過100毫秒!
也就是說,現在在CPU上跑大模型,著實是更香了。
而這也僅是英特爾在此次發布中的一隅,還包括打破自家“祖制”、被稱為四十年來最重大架構轉變的酷睿?? Ultra。
此舉亦是將AI的power注入到消費級PC中,用于加速本地的AI推理。
除此之外,具體到英特爾長期在各行各業扎根的AI實戰應用,包括數據庫、科學計算、生成式AI、機器學習、云服務等等,也隨著第五代至強?? 可擴展處理器的到來,在其內置的如英特爾?? AMX、英特爾?? SGX/TDX等其他內置加速器的幫助下,得到了更大的降本增效。
總而言之,縱觀英特爾此次整場的發布,AI可謂貫穿始終。
最新英特爾處理器,AI更Power了
我們先來繼續深入了解一下第五代至強?? 可擴展處理器披露的更多細節。
例如在性能優化方面,英特爾將各種參數做了以下提升:
● CPU核心數量增加到64個,單核性能更高,每個內核都具備AI加速功能
● 采用全新I/O技術(CXL、PCIe5),UPI速度提升
● 內存帶寬從4800 MT/s提高至5600 MT/s
我們再來縱向,與英特爾前兩代產品做個比較,那么性能提升的結果是這樣的:
● 與上一代產品相比,相同熱設計功耗下平均性能提升21%;與第三代產品比,平均性能提升87%。
● 與上一代產品相比,內存帶寬提升高達16%,三級緩存容量提升至近3倍之多。
不難看出,第五代至強?? 可擴展處理器與“前任們”相比,在規格與性能上著實是有了不小的提升。
但英特爾可不僅僅是披露,而是已經將第五代至強?? 可擴展處理器用起來,并把實打實的使用效果展示了出來。
例如在大模型的推理方面,京東云便在現場展示了搭載第五代至強?? 可擴展處理器的新一代自研服務器所呈現的能力——
全部以超過20%的性能提升“姿勢”亮相!

具體而言,京東云與上一代自研服務器有了如下的性能提升:
● 整機性能提升達123%;
● AI計算機視覺推理性能提升至138%;
● Llama 2推理性能提升至151%。
這也再一次證明了在五代至強?? 上搞大模型,是越發得吃香了。
而除了大模型之外,像涉及AI的各種細分領域,如整機算力、內存寬帶、視頻處理等等,也有同樣的實測結果。
這份結果則是來自采用了第五代英特爾? 至強? 可擴展處理器的火山引擎——
其全新升級的第三代彈性計算實例,整機算力提升39%;應用性能最高提升43%。

而且在性能提升的基礎上,據火山引擎透露,通過其獨有的潮汐資源并池能力,構建了百萬核彈性資源池,能夠用近似包月的成本提供按量使用體驗,上云成本更低了!
這是由于使用內置于第五代至強?? 可擴展處理器中的加速器時,可將每瓦性能平均提升10倍;在能耗低至105W的同時,也有已針對工作負載優化的高能效SKU。
可以說是實打實的降本增效了。
在云計算和安全性方面,亮出實測體驗的同樣是來自國內的大廠——阿里云。
在搭載第五代英特爾? 至強? 可擴展處理器及其內置的英特爾? AMX、英特爾? TDX加速引擎后,阿里云打造了“生成式AI模型及數據保護“的創新實踐,使第8代ECS實例在安全性和AI性能上都獲得了顯著提升,且保持實例價格不變,普惠客戶。
包括推理性能提高25%、QAT加解密性能提升20%、數據庫性能提升25%,以及音視頻性能提升15%。

值得一提的是,內置的英特爾?? SGX/TDX還可以為企業分別提供更強也更易用的應用隔離能力和虛擬機 (VM) 層面的隔離和保密性,為現有應用提供了一條更簡便的向可信執行環境遷移的路徑。
以及第五代英特爾? 至強? 可擴展處理器在軟件和引腳上是與上一代兼容的,還可以大大減少測試和驗證工作。
總的來說,第五代至強? 可擴展處理器可謂“誠意滿滿”、表現非常亮眼,而它背后所透露出來的,正是英特爾在AI領域一直都非常重視落地的態度。
背后是一部AI落地史
事實上,作為服務器/工作端芯片,英特爾? 至強? 可擴展處理器從2017年第一代產品開始就利用英特爾?? AVX-512技術的矢量運算能力對AI進行加速上的嘗試;而2018年在第二代至強?? 可擴展處理器中導入深度學習加速技術(DL Boost)更是讓至強成為“CPU跑AI”的代名詞;在之后第三代到第五代至強?? 可擴展處理器的演進中,從BF16的增添再到英特爾?? AMX的入駐,可以說英特爾一直在充分利用CPU資源的道路上深耕,以求每一代處理器CPU都能支持各行各業推進AI實戰。
起先是在傳統行業。
例如第二代至強?? 就發力智能制造,幫助企業解決海量實時數據處理挑戰,提升生產線系統效率,完成“肉眼可見”的產能擴展。
隨后,至強? 可擴展處理器開始在大模型界大展身手。
在AlphaFold2掀起的蛋白質折疊預測熱潮之中,第三代和第四代至強? 可擴展處理器連續接力,不斷優化端到端通量能力。實現比GPU更具性價比的加速方案,直接拉低AI for Science的入場門檻。

這其中就有從第四代開始內置于CPU中,面向深度學習應用推出的創新AI加速引擎——英特爾? AMX的功勞。作為矩陣相關的加速器,它能顯著加速基于CPU平臺的深度學習推理和訓練,提升AI整體性能,對INT8、BF16等低精度數據類型都有著良好的支持。
與此同時,在大模型時代的OCR技術應用,也被第四代至強? 可擴展處理器賦予了新的“靈魂”,準確率飆升、響應延遲更低。
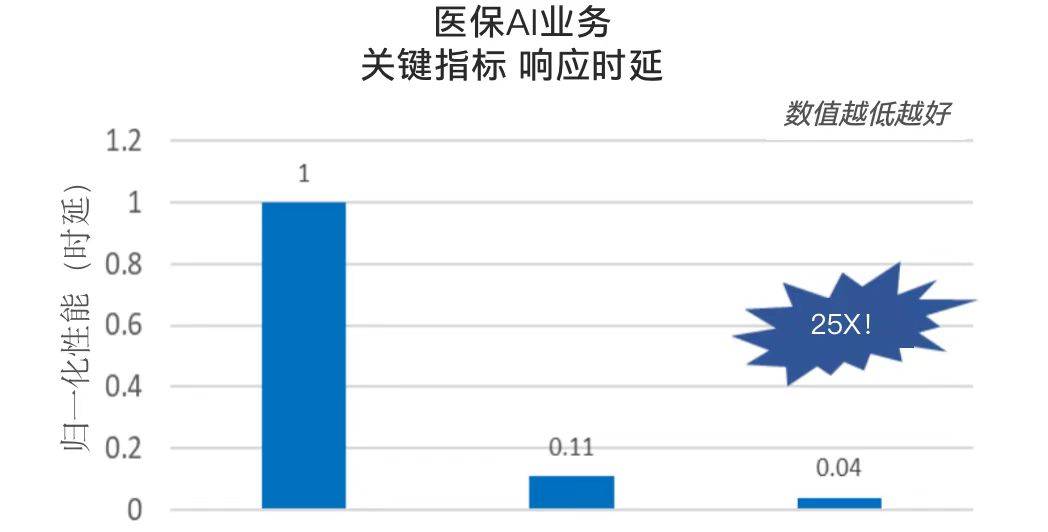
同樣,就在不久之前,借助第四代至強?? 可擴展處理器在NLP上的優化,專攻醫療行業的大語言模型也成功以較低成本在醫療機構部署落地。
在AI技術越來越深入各行各業的大趨勢之下,至強? 可擴展處理器讓我們看到,它所代表的CPU解法完全能夠有所作為、能夠讓不少AI應用在部署更為廣泛、獲取更加容易、應用門檻也更低的CPU平臺上獲得實實在在的落地開花。
第五代至強? 可擴展處理器的發布,則讓這個進程更進一步。
當然——
這一成績的背后,確實是因為大家對“在CPU上跑AI”這件事上有需求,以及它本身也有極其深厚的價值和優勢。
先說需求,無論是傳統企業推進智能化改造,還是AI for Science、生成式AI等新興技術的蓬勃發展,都需要強大的算力來驅動。
但大家面臨的局勢卻是:專門的加速芯片供不應求,采購難不說,成本也十分高昂,因此還遠遠不夠普及。
于是一部分人自然將目光投向CPU:
這個現實中最為“觸手可及”的硬件,如果直接加以利用,豈不是事半功倍?
這就引出CPU的價值和優勢。
就拿當下熱門話題生成式AI來說,如果想在生產環境中普及這一能力,就得盡可能地控制成本。
相比訓練來說,AI的推理對算力資源需求沒有那么夸張,交給CPU完全能夠勝任——不僅延遲更低,能效也更高。
像一些行業和業務,推理任務沒有那么繁重,選擇CPU無疑更具性價比。
此外,利用CPU直接進行部署還能讓企業充分利用既有IT基礎設施,避免異構平臺的部署難題。
以上,我們也就能夠理解:在傳統架構中引入AI加速,就是CPU在這個時代的新宿命。
而英特爾做的,就是竭盡全力幫大家挖掘、釋放其中的價值。
駕馭整個AI管線,且不止CPU
最后,我們再回到今天的主角:第五代英特爾? 至強? 可擴展處理器。

實話說,如果和專門的GPU或AI加速芯片相比,它可能確實還不夠炫,但主打親民、易用(開箱即用,配套的軟件和生態越發完善)。
更值得我們注意的是,就算在有專用加速器的場合,CPU無論是從數據預處理,還是模型開發和優化,再到部署和使用,也可以成為AI pipeline的一部分。
其中尤其在數據預處理階段,它已可以稱得上是主角的存在。
無論是以GB還是TB計,甚至更大的數據集,基于至強? 可擴展處理器所打造的服務器,都能通過支持更大內存、減少I/O操作等優勢,提供高效的處理和分析,節省AI開發中這一最瑣碎耗時任務的時間。
基于以上,我們也不得不感嘆,如今英特爾在談AI時,話題更多樣化了。
再加上它在GPU和專門的AI加速芯片上也有布局,“武器庫”里的選擇也更多了,火力覆蓋的能力也更全面了。
毫無疑問,這一切,都指向英特爾全面加速AI的決心。
即用一系列具有性價比的產品組合來快速滿足不同行業的AI落地需求。
AI 落地時代開始了,英特爾的機會也來了?

關鍵詞:











